电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:Jenny.Zhang
发布时间:2022.11.1
浏览次数:1,823 次浏览
随着大数据业务的不断开展,各大互联网公司都非常重视数据价值的挖掘。
在公司的日常运行中,各种数据分析挖掘技术,为公司发展决策和业务开展提供数据支持。作者所在的公司内部也形成了一套完善的数据治理方案,核心就是由大数据平台+数据仓库+数据治理平台+数据监控平台来实现数据治理。
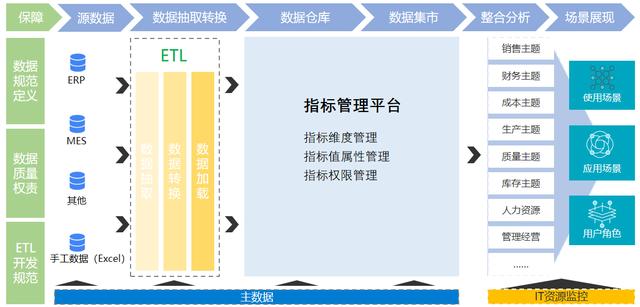
1.大数据平台支撑整个大数据的运行环境
2.数据仓库整合各个业务线的数据,消灭数据烟囱
3.数据治理平台提供统一指标管理、统一维度管理、统一数据出口管理
4.数据质量负责监控数据资产质量状态、持续推动数据质量监控优化预警、实时监控预警
公司业务的不断发展加快了数据膨胀的速度,数据不一致等问题也随之而来。同时业务部门的频繁增加和剥离也会对数据治理带来挑战。
例如:不同业务线之间没有统一的数据入口记录和加工业务的发展过程;不同业务线的数据分析人员、数据开发人员,不同产品线之间缺乏有效的沟通,人员的流动也会产生一系列对接问题。
1.各个数据平台和业务系统不同模块的指标定义不一致
2.相同指标名称对应计算口径不一致
3.指标数据来源不一致
上述问题最终带来的后果就是指标数据可信度低,从而严重影响数据分析决策。
数据治理不仅需要完善的保障机制,还需要具体的治理内容,比如我们的数据怎样规范、元数据怎么来管理、每个过程都需要哪些系统或者工具来配合呢,这些都是数据治理过程中最实际的问题,今天我们将从数据治理的核心领域来解答这些问题。
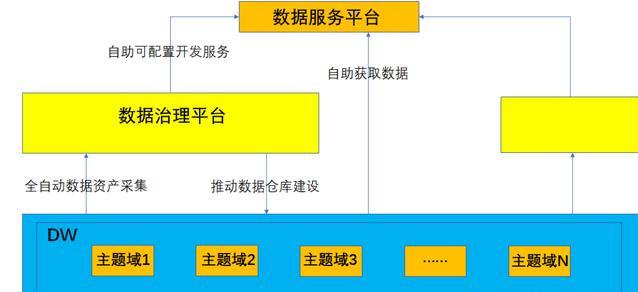
如上图所示,对于数据仓库层,数据治理平台综合业务的组织形式、指标数据来源、指标定义规则、上层产品使用以及查询的效率指导数据仓库模型建设;
对于数据服务层的产品,业务元数据以及数据元数据均由数据治理平台提供,这样能够保障产品获得信息的一致性,同时也减少了对底层数据的侵入。
数据治理平台的核心是保障数据一致性,同时在保障数据安全和一致性的基础上,尽力提供高可用的数据服务分发能力。保障数据一致性需要在建设的过程中不断进行抽象,形成具有相对单一功能的模块,合理组织模块层级间的关系。
提高数据治理平台的可用性主要包括如下领域的治理。
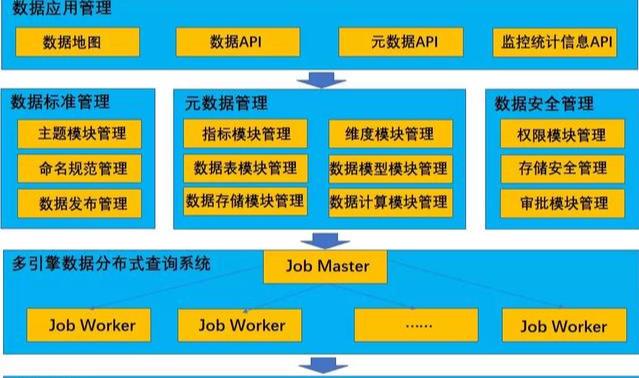
如上图所示,数据治理平台主要包括数据存储、数据查询、元数据管理、安全管理、数据标准管理和数据应用管理等。
各领域之间需要有机结合,数据标准、元数据、数据质量等几个领域相互协同和依赖。例如数据标准管理可以提升数据合法性、合规性,进一步提高数据质量,减少数据生产问题。
数据治理平台的数据存储主要包括:数据仓库宽表/主题表层和数据应用层,存储方式包括:Hive、Kylin、ClickHouse、Druid、MySql。
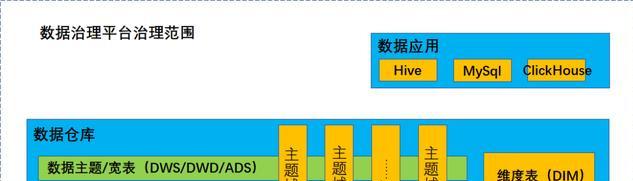
上图所示的数据存储中的数据加工过程,均由数据开发工程师负责;具体采用哪种存储介质由数据架构师和数据开发工程师综合所需的数据存储空间、查询效率、数据模型组织形式等因素共同决定。
但是后续的使用维护均由数据治理平台来统一管理,主要是通过管理数据表元数据信息查询实现。
数据存储托管之后,数据表元数据信息变更监控、表数据生产(存储空间、生产状态及完成时间)监控、表数据波动(同环比)监控以及表的使用(模型构建及查询效率等)监控及评估,都由数据治理平台自动完成,任何信息的变动都会自动通知对应的负责人,以保障数据应用的安全和稳定。
元数据分为业务元数据、数据元数据和操作元数据,三者之间紧密相连。业务元数据指导数据元数据,数据元数据以业务元数据为参考进行设计,操作元数据为两者的管理提供支撑。
1.业务元数据:业务元数据是定义和业务相关数据的信息,用于辅助定位、理解和访问业务信息。
2.数据元数据:数据元数据结构性数据元数据和关联性数据元数据。
3.操作元数据:操作元数据主要指与元数据管理相关的组织、岗位、职责、流程,以及系统日常运行产生的操作数据。
数据表模块管理涉及数据库信息和数据表信息。其中数据库信息包括数据库链接信息,数据治理平台可以自动获取维护后的数据库信息所对应库中的元数据信息。
数据表信息包括:表的元数据信息(引擎、字段、描述等)、表类型(事实表、维度表)、表的使用情况(是否被模型引用)、表对应的ETL、负责人、监控报警配置、样例数据等。
上述信息为业务用户提供指导,为模型管理提供数据支持,也为数据表和数据的稳定性提供监控和预警。

模型模块管理能够还原业务落地后数据表的组织关系,包括:数据表的关联方式(join、left outer join、semi join等)、数据表的关联限制(where)、模型ER图、模型包含字段、模型字段与维度的绑定关系、模型与指标的绑定关系。
由于数据治理平台主要是针对数据分析使用的,所以主要的模型包括维度模型中的星型模型和雪花型模型。
指标模块管理包括基础信息、衍生信息和技术信息管理。衍生信息包括关联指标、关联应用管理。基础信息对应的就是指标对应的业务过程信息,由业务人员编写,主要包括指标名称、业务分类、统计频率、精度、单位、指标定义、计算逻辑、分析方法、分析维度等;
基础信息中还有一个比较重要的部分是监控配置,主要是配置指标的有效波动范围区间、同环比波动区间等,监控指标数据的正常运行。
技术信息主要包括数据类型、指标代码,其中核心部分是指标与模型的绑定关系,通过配置对应的计算公式,或者还包括一些额外的高级配置,如二次计算、模型过滤条件等。
在数据资源管理过程中,作者经过不断地实践慢慢摸索出一套适合大数据的存储优化方法,可在元数据的基础上,诊断、加工成多个存储治理项目。
目前已有的存储治理优化项有未管理表、空表、最近93天未访问表、数据无更新无任务表、数据无更新有任务表、开发库数据大于100GB且无访问表、长周期表等。
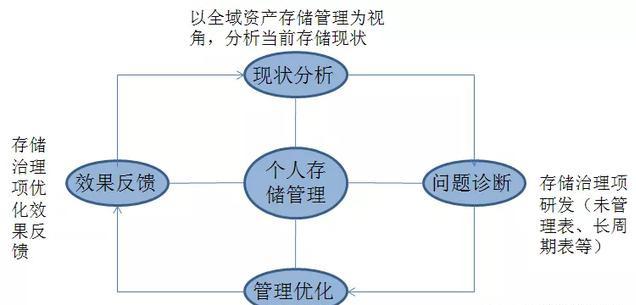
生命周期管理的根本目的就是用最少的存储成本来满足最大的业务需求,使数据价值最大化。
1.周期性删除策略:所存储的数据都有一定的有效期,从数据创建开始到过时,可以周期性删除已过有效期的X天前的数据。如果某些历史数据可能已经没有价值,且占用存储成本,则可针对无效的历史数据就可以进行定期清理。
2.测底删除策略:无用表数据或者ETL过程产生的临时数据,以及不需要保留的数据,可以进行及时删除,包括删除元数据。
3.永久保留数据:重要且不可以恢复的底层数据和应用数据需要永久保留,例如底层交易的增量数据,出于存储成本与数据价值相权衡的考虑,需要永久保留,以备用于历史数据的恢复与核查。
4.冷数据管理策略:冷数据策略是永久保留策略的扩展。永久保留的数据需要迁移到冷数据中心永久保存。
大型互联网公司的集群上面有几十万甚至几百万的任务,每天存储资源、计算资源消耗都很大。如何降低计算资源的消耗,提高任务执行的性能,提升任务产出的时间,是计算平台和ETL开发工程师孜孜追求的目标,下面将重点介绍任务优化。
SQL/MR作业一般会生成MapReduce任务,在Hadoop中则会生成唯一一个job_id进行标识。
1.Map倾斜:每个输入分片会让一个Map Instance来处理,默认情况下,以系统中一个文件块的大小(默认为256MB)为一个分片。Map Instance输出的结构会暂时放在一个环形内存缓冲区中,当该缓冲区快要溢出时会在本地文件系统中创建一个溢出文件,即Write Dump。在Map读数据阶段,可以通过“SET odps.mapper.split.size=256”来调节Map Instance的个数,提高数据读入的效率,同时也可以通过“SET odps.mapper.merge.limit.size=64”来控制Map Instance读取文件的个数。如果输入数据的文件大小差异比较大,那么每个Map Instance读取的数据量和读取时间差异也会很大。
2.在写入磁盘之前,线程首先根据Reduce Instance的个数划分分区,数据会根据Key值Hash到不同的分区上,一个Reduce Instance对应一个分区的数据。Map端也会做部分聚合操作,以减少输入Reduce端的数据量。由于数据是根据Hash分配的,因此会导致有些Reduce Instance会分配到大量数据。
在Map端读数据时,由于读入数据的文件大小分布不均匀,因此会导致有些Map Instance读取并且处理的数据特别多,而有些Map Instance处理的数据特别少,造成Map端长尾。以下两种情况会造成Map端长尾:
1.上游表文件的大小特别不均匀,并且小文件特别多,导致当前表Map端读取的数据分布不均匀,引起长尾。
2.Map端做聚合时,由于某些Map Instance读取文件的某个值特别多而引起长尾,主要是指Count Distinct操作。
第一种情况导致的Map长尾,可以对上游数据合并小文件,同时调节本节点的小文件的参数来进行优化,即通过设置“SET odps.sql.mapper.merge.limit.size=64”和“SET odps.sql.mapper.split.size=256”两个参数来调节,其中第一个参数用于调节Map任务的Map Instance的个数;
第二个参数用于调节单个Map Instance读取的小文件个数,防止由于小文件过多导致Map Instance读取的数据量很不均匀。
第二种情况导致的Map长尾,可以通过distribute by rand()会将Map端分发后的数据重新按照随机值再进行一次分发,避免Map端长尾。
数据安全管理是数据治理平台的核心功能之一,分为平台操作权限管理和接口调用权限管理。
1.保障提供数据指标定义、计算口径、数据来源一致性。
2.保障维度定义、维度值一致性。
3.保障维度和指标元数据信息的唯一出口。
4.提供维度和指标数据统一监控及预警能力。
商业智能BI产品更多介绍:www.finebi.com