电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:Jenny.Zhang
发布时间:2022.11.1
浏览次数:964 次浏览
炎炎夏日,长裤已难以满足广大男生的需求,为了在搬砖和摆摊的过程中增添一丝舒适感,他们开始寻找一种神奇的存在——大裤衩。我在种菜的这些日子里也日益感受到大裤衩的重要性,于是,打开电脑并抓取了淘宝4403条大裤衩数据,进行了数据可视化分析,并最终找到一条可以入手的大裤衩。
本文主要尝试解决以下几个问题:
1.国内哪些地方的大裤衩卖的比较好?
2.大裤衩市场价格是怎样的?
3.哪些店铺大裤衩销量较高?
4.在售的大裤衩具有哪些特点?
淘宝网站是一个ajax动态加载的网站,只能通过解析接口或用selenium自动化测试工具去爬取。
本次数据获取采用selenium,由于我的谷歌浏览器版本更新较快,导致原来的谷歌驱动失效。于是,我禁用了浏览器自动更新,并下载了对应版本的驱动。
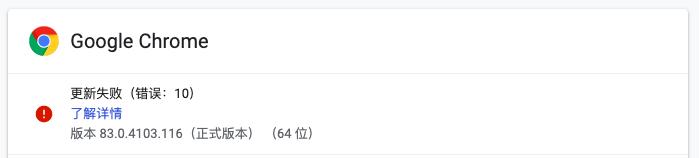
浏览器版本
浏览器驱动必须与浏览器版本匹配,否则selenium将失效。
接着,我利用selenium在淘宝网搜索大裤衩,手机扫码登录,获得了大裤衩的商品名称、商品价格、付款人数、店铺名称、发货地址等信息。
def main():
browser.get('https://www.taobao.com/')
page = search_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("-" * 100)
print("正在爬取第{}页大裤衩数据".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num*44))
browser.implicitly_wait(10)
get_data()
page_num += 1
print("大裤衩数据抓取完成")
if __name__ == '__main__':
key_word = "大裤衩 男"
browser = webdriver.Chrome("./chromedriver")
main()短短几分钟就爬下了4403条大裤衩样本数据,为了方便数据分析,还需要对原始数据进行简单清洗。
import pandas as pd
import numpy as np
df = pd.read_csv('big_pants.csv',header=None,
names=['商品名称','商品价格','付款人数','店铺名称','发货地址']) #添加字段名称
df.sample(5) #预览数据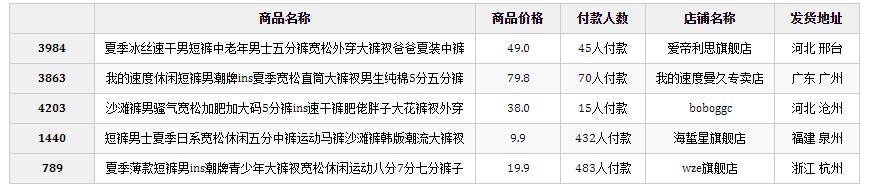
df = df.drop_duplicates() df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3835 entries, 0 to 4402
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 商品名称 3835 non-null object
1 商品价格 3835 non-null float64
2 付款人数 3835 non-null object
3 店铺名称 3835 non-null object
4 发货地址 3822 non-null object
dtypes: float64(1), object(4)
memory usage: 179.8+ KBdf.dropna(axis=0, how='any', inplace=True)listBins = [0, 50,100, 150, 200, 500,1000000] #设置切分区域
listLabels = ['50及以下','51-100','101-150','151-200','201-500','500及以上']#设置切分后对应标签
df['价格区间'] = pd.cut(df['商品价格'], bins=listBins, labels=listLabels, include_lowest=True) #利用pd.cut进行数据离散化切分df["省份"] = df["发货地址"].str.split(' ',expand=True)[0] #expand=True可以把用分割的内容直接分列
#df['省份'] = df['发货地址'].str.split(' ').apply(lambda x:x[0]) #提取省份
df["城市"] = df["发货地址"].str.split(' ',expand=True)[1] #提取城市
df["城市"].fillna(df["省份"], inplace=True) #城市字段空值用省份非空值填充import re
df['数字'] = [re.findall(r'(\d+\.{0,1}\d*)', i)[0] for i in df['付款人数']] # 提取数值
df['数字'] = df['数字'].astype('float') # 转化数值型
df['单位'] = [''.join(re.findall(r'(万)', i)) for i in df['付款人数']] # 提取单位(万)
df['单位'] = df['单位'].apply(lambda x:10000 if x=='万' else 1)
df['付款人数'] = df['数字'] * df['单位'] # 计算付款人数# 删除多余的列
df.drop(['发货地址', '数字', '单位'], axis=1, inplace=True)
#按商品价格降序
df = df.sort_values(by="商品价格", axis=0, ascending=False)
# 重置索引
df = df.reset_index(drop=True)
df.head(10) 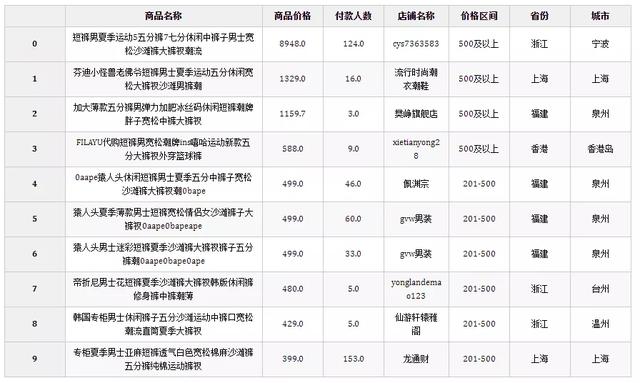
数据清洗干净后,接下来就可以做可视化分析了,本次可视化分析主要用到Python的pyecharts库和BI工具。
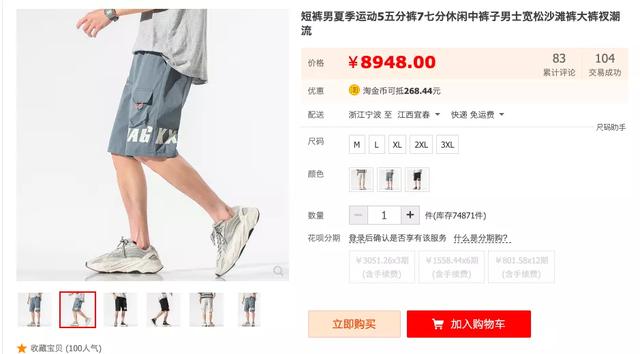
我们首先来看点有意思的数据,最贵的大裤衩和最便宜的大裤衩的区别。
最贵的大裤衩:
最便宜的大裤衩:
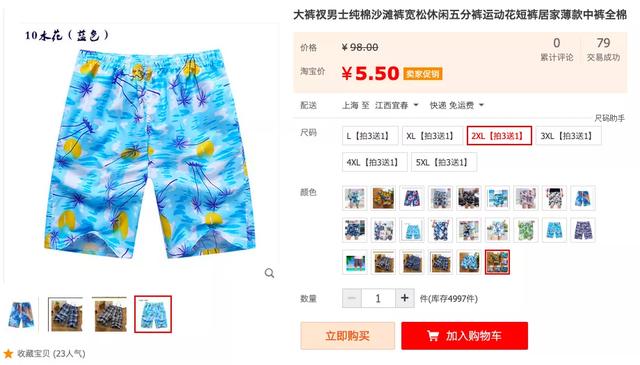
对比一下,不难发现这两条大裤衩的区别,一个风度翩翩,一个花里胡哨。作为一名种菜的民工,风度没卵用(主要还是买不起),便宜无好货的认知在开始学种菜的时候就印刻在我的脑海里了,于是我继续分析。
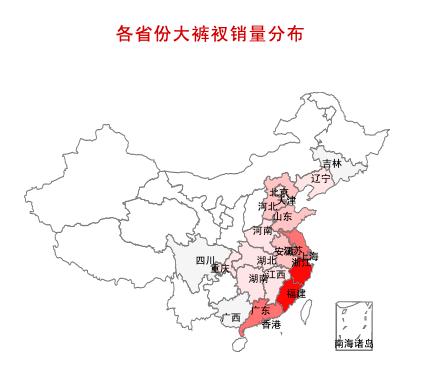
我利用省份和付款人数字段数据做了个全国地图,发现福建和浙江这两个地方盛产大裤衩。根据一般的经济学原理,产业集聚更容易带来专业化分工和规模化经营。于是,我首先锁定了这两个地方的大裤衩并进一步下钻分析。
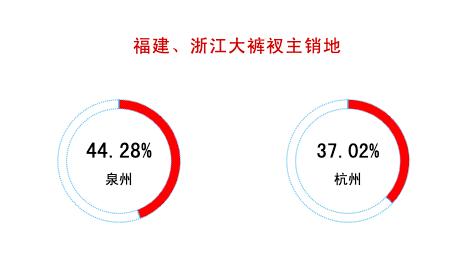
在盛产大裤衩的两个省份中,泉州占到了福建大裤衩的44.28%,杭州占到了浙江大裤衩的37.02%。目标进一步缩小,我内心无比激动。
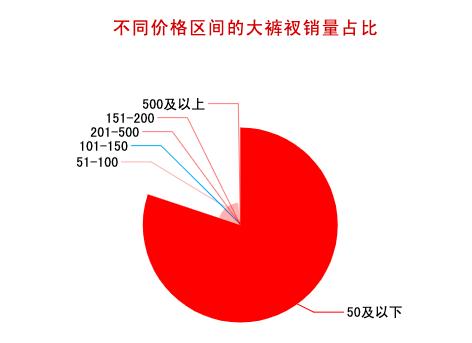
要想买到一条合适的大裤衩,不仅需要分析销量因素,咱们还得分析价格因素。由上图可知,80%的大裤衩价格在50元以下,100元以上的大裤衩占比不到2%。可见,大家对大裤衩的心理价位普遍不高。
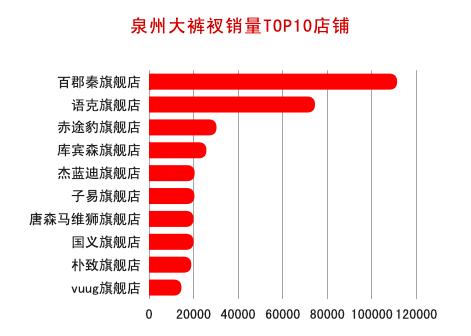
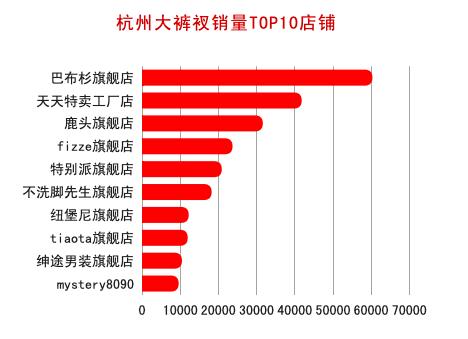
从销量较高的淘宝店铺来看,基本都是旗舰店,看来大家对店铺品牌效应关注度较高。我也查了下mystery8090,这是一家专注胖男孩的韩流服饰店,市场定位还是不错的,难怪也获得了不错的销量。

我为了了解大裤衩的特点,对商品名称字段做了文本分析,以浴缸为背景绘制了大裤衩词云图。主要的特点基本上还是看的出来的,在售的大裤衩大都具有宽松、休闲、短、潮流等特点。
我根据以上分析,同时查看了相关的宝贝评价、好评率等指标,综合分析后,终于找到了以下大裤衩并入手。我不经感慨,再也不怕种菜的时候热出翔了!

商业智能BI产品更多介绍:www.finebi.com