电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:FineBI
发布时间:2023.9.15
浏览次数:6,283 次浏览
FineBI6.0的升级带来了一个全新的函数——DEF函数,据说它能够解决分析师新建指标的难题;近期也有不少用户来找大师兄咨询“这个函数,到底该怎么玩?”
不管之前是否听说过这个函数,各位看官今天不妨花个5分钟,听我和你唠一唠这个DEF函数。
做bi数据分析,你一定遇到过这个情况:数据处理的差不多了,正准备进行一场行云流水的可视化分析,结果一个指标在组件里不会算,卡壳了。头疼了半天,最后还是回到数据集去做处理。一天的好心情就此宣告结束。
如果你还是没什么印象,那看看以下几个场景:
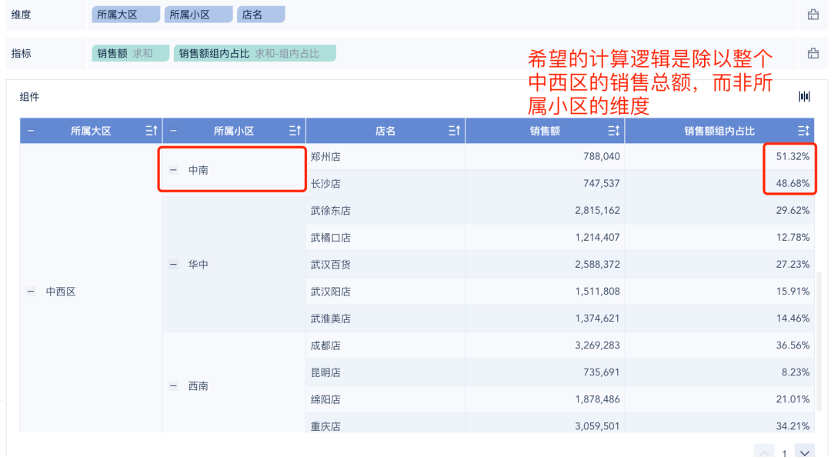
1、使用快速计算配置的组内占比,但是维度比较多,包含几个层级,没办法算出我实际想要的组内占比。(指定维度级别的计算)
2、我想计算近三个月销售额的平均值,比如5月的就计算3、4、5三个月的平均值,6月的就计算4、5、6三个月的平均值,以此类推。这其实是行间的滚动计算。组件内不太好做,数据集里处理也是相当麻烦。
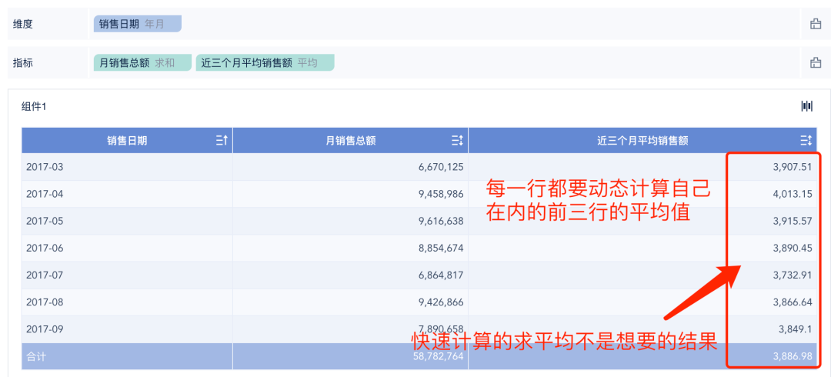
具体以前是怎么解决的,我们先不讨论,但本来流畅的分析仅因一个指标算不出而被打断,真的是一件令人难受的事情。
今天咱要聊的DEF函数的价值就在于此:提供指定维度级别的计算、行间计算以及嵌套视图计算的强大能力,让你在新建指标的过程中不再受阻。
指定维度?行间计算?有些不太理解,没关系,咱们先简单学习下它。
DEF,即define的缩写,意为定义你想要的所有指标。在当前FineBI6.0版本中,你可以在分析主题的数据层以及在组件中创建计算字段时使用它。
DEF(聚合指标, [维度1,维度2,...], [过滤条件1, 过滤条件2,...]) 其中维度和过滤条件可以缺省。
它由三个参数构成,首先是定义计算的方式,即语法中的“聚合指标”。第二个是执行聚合计算时的维度,第三个则是计算前对数据的过滤条件。这里举两个例子帮助大家理解:
1、计算每个省份不同产品的销售总额:DEF(sum_agg(销售额),[省份,产品])解释:参数2-维度中我们选择了【省份】和【产品】两个字段,因此基于这两个维度对参数1中的【销售额】字段进行【sum_agg】计算,即求和。
2、计算2013年各省的销售总额:
DEF(sum_agg(销售额),[省份],[年份=2013])
解释:参数2-维度中我们选择了【省份】,于是基于“省份”对参数1中的【销售额】字段进行【sum_agg】计算,同时,由于参数3-过滤条件中,限制了年份要2013年,所以只得出2013年的销售总额。
再给大家举个例子:
RFM客户价值分析大家并不陌生。这一分析最主要的部分是新建三个指标,即R-最近一次消费时间,F-最近一段时间内消费频次,M-最近一段时间内消费金额。然后基于这些特征,将客户的重要性进行划分。
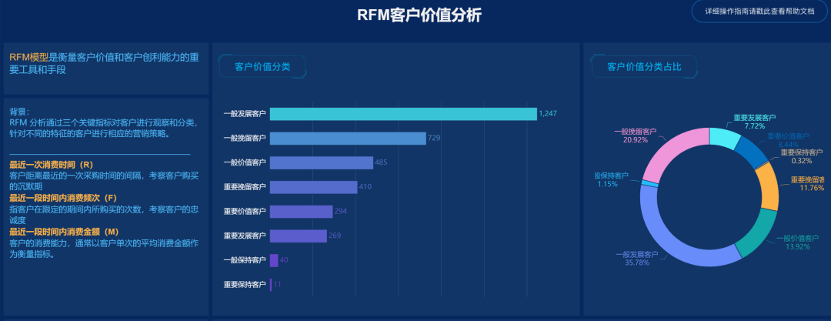
假设我们的基础明细表拥有以下字段【合同ID】【合同金额】【公司名称】【签单时间】,你要如何用DEF函数求出每个客户公司的RFM?
DEF(COUNT_AGG(合同ID),[公司名称])
DEF(SUM_AGG(合同金额),[公司名称])
DEF函数已经发布有一段时间了,研究过的小伙伴可能会注意到与他配合使用的另一个函数-Earlier。Earlier带来了“选取当前行”的能力,接下来我们通过刚才说的转化率的场景来认识他。
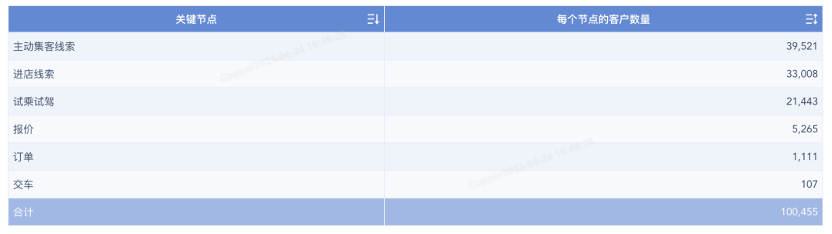
我想求出每一节点的转化率,即当前节点客户数量/上一节点客户数量。听起来很容易,但是在实际操作的时候,马上就愣住了:“我要怎么取到上一行的数据呢?”,这就是一种行间的计算,我在这里给大家推荐一种做法,希望能给你们带来一些启发。
首先,通过一个简单的DEF函数求出每个关键节点的客户数量:DEF(SUM_AGG({客户数}),{关键节点})
然后,通过DEF函数求出每个节点对应的序号:DEF(COUNTD_AGG({关键节点})+1,[{关键节点}],[{每个节点的客户数量}>EARLIER({每个节点的客户数量})])

这看起来是个很复杂的公式,让我们一点一点来理解他。
counted_agg(关键节点)+1:对关键节点进行计数,并且结果+1。其中难理解的点在于公式中过滤条件这一参数:{每个节点的客户数量}>EARLIER({每个节点的客户数量},它看起来像是自己大于自己,乍一看完全不明白其中的逻辑。
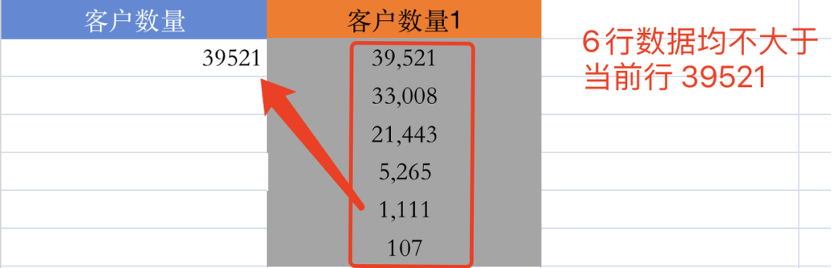
为了便于大家理解,如下图,我在这里添加一列辅助列【客户数量1】。回到这个式子,{每个节点的客户数量}>EARLIER({每个节点的客户数量},还记得我们说过earlier是选取当前行吗?
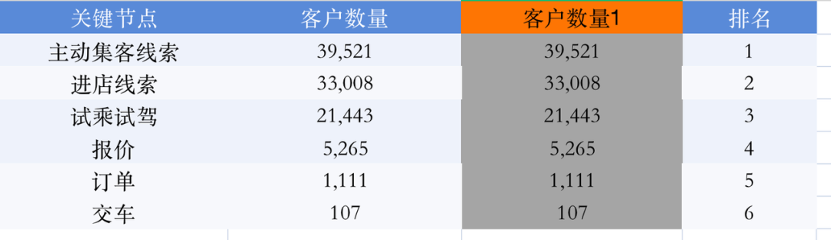
从第一行来看,这个大于号的意思是,【客户数量1】比【客户数量】字段的当前行(即39521)大的节点。可以看到【客户数量1】字段六行数据均不大于39521,因此符合条件的节点数量为0。又因为我们在counted结果后写了一个“+1”,所以最后【排名】字段在第一行输出了1的结果。
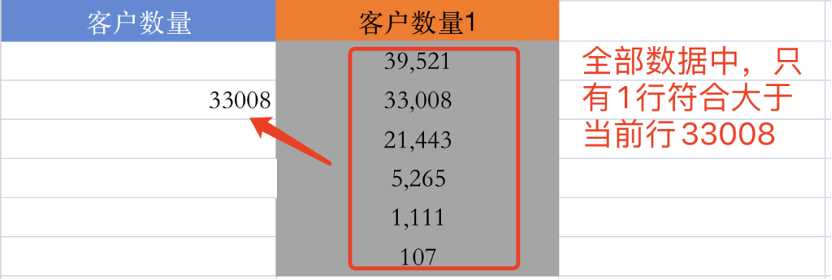
同理,计算第二行时只有1个节点比33008大,+1后输出2,以此类推,最终可以根据客户数量为节点进行排序。
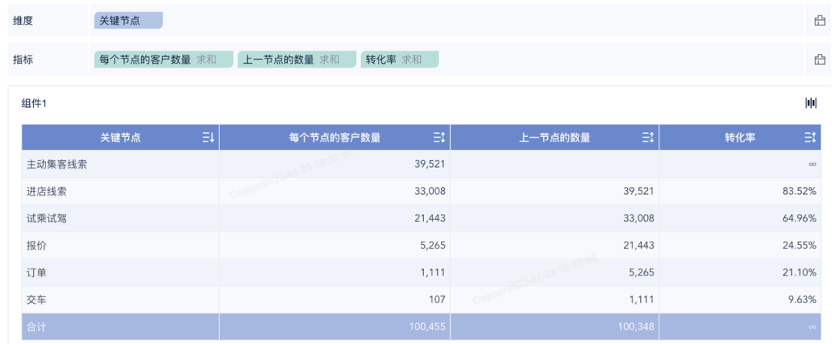
得出序号后,就可以通过DEF(SUM_AGG(${每个节点的客户数量}),[${关键节点}],${排序}+1=EARLIER(${排序}))
求出对应的上一节点数量,以此进一步求得转化率。
今天我们聊了很多高级分析、高级函数,但数据分析本身并不是越高级越复杂越好。函数也好,分析方法也罢,说到底都是帮助我们发现问题,解决问题的工具。DEF函数亦是如此,它可以让你在一些场景更快得到需要的指标。但并不是说我们所有的分析都要用它来解决,不要让工具限制我们的思考。
较低的上手门槛和没有上限的分析能力一直是我们的追求,未来我们也将不断封装常用的DEF函数计算供大家直接使用,借此带来更好的分析体验。也欢迎大家前往我们的FineBI社区论坛,同更多数据分析爱好者进行交流。
商业智能BI产品更多介绍:www.finebi.com