电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
电话咨询:400-811-8890
作者:Jenny.Zhang
发布时间:2024.3.13
浏览次数:8,929 次浏览
在当今信息爆炸的时代,大量的数据被积累、存储和传输,数据分析成为从这海量信息中提炼洞见的关键工具。数据分析方法千差万别,涵盖了统计学、机器学习、可视化等多个领域。这篇文章将深入探讨数据分析的各种方法,从描述性统计到机器学习,从探索性数据分析到空间数据分析,旨在为读者提供全面而系统的了解。

描述性统计分析是统计学中的一个分支,其目的是通过概括和总结数据集的主要特征,来提供对数据的直观理解。这种数据分析方法主要关注数据的集中趋势、分散程度和分布形状等基本统计特征。

描述性统计分析通常通过以下几个方面展现数据:
探索性数据分析是由统计学家John W. Tukey提出的一种数据分析方法,旨在通过绘图和统计手段,深入理解数据集的结构、特征和模式,发现潜在的趋势和异常,为后续深入分析和建模提供基础。EDA的目标不是进行严格的推论统计,而是对数据进行初步的、直观的、全面的探索。
EDA的主要特点包括:
推论统计学是统计学的一个分支,主要关注从样本中得出关于总体的信息。它通过对样本统计量的分析和推断,帮助我们了解总体的性质、做出预测或者对总体参数进行推断。
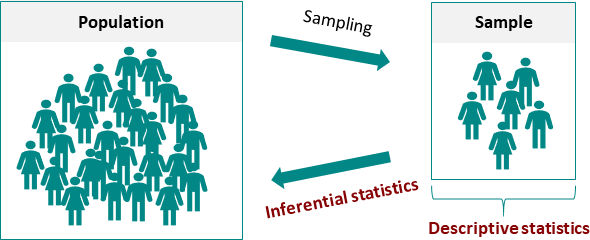
推论统计学主要包括两个方面:
1)参数估计:利用样本数据估计总体参数的值,包括点估计和区间估计。点估计给出一个单一值作为总体参数的估计,而区间估计则提供参数估计的区间,表示我们对总体参数的不确定性。
2)假设检验:假设检验是统计学中一种常用的方法,用于对某个关于总体参数的假设进行检验。该方法基于样本数据,通过对比观察到的统计值与在零假设下的理论期望值之间的差异,来评估是否可以拒绝零假设。假设检验通常包括以下步骤:
回归分析是一种统计学方法,用于研究自变量与因变量之间的关系。通过建立数学模型,回归分析旨在揭示自变量的变化如何影响因变量的变化,以及这种影响的程度和方向。

回归分析可分为两大类:
聚类分析是一种无监督学习方法,旨在将数据集中的观察值划分为相似的组,这些组被称为簇(Cluster)。聚类的目标是使同一簇内的观察值相似度较高,而不同簇之间的相似度较低。通过聚类,我们可以发现数据中的内在结构、识别模式,并将相似的观察值划分为同一组,有助于深入理解数据。
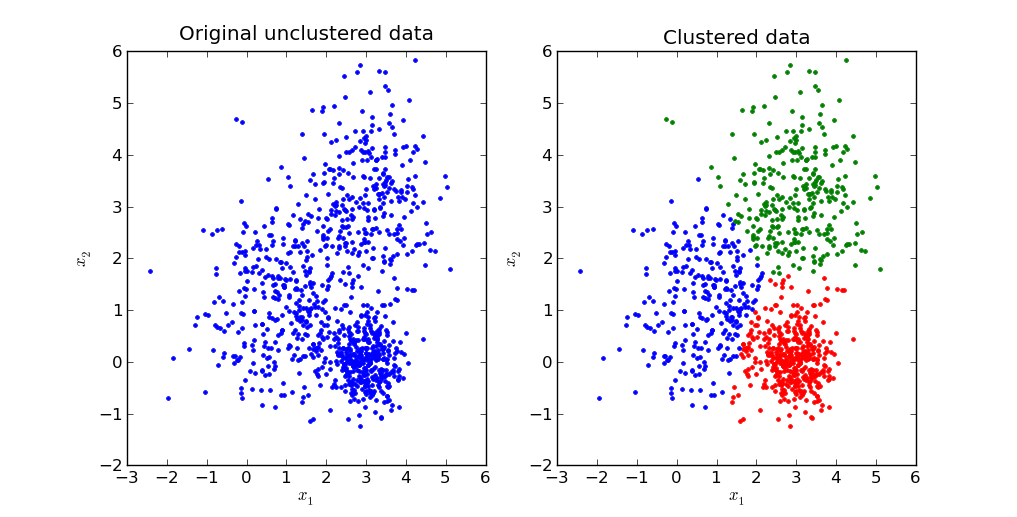
聚类分析在许多领域中都有广泛应用,例如:
关联规则挖掘旨在发现数据集中不同项之间的关联关系。这些关联规则描述了一个事件或者集合中出现的模式,指出在给定一些条件下,其他条件也可能会发生。常见的应用包括购物篮分析、交叉销售、网络流量分析等。
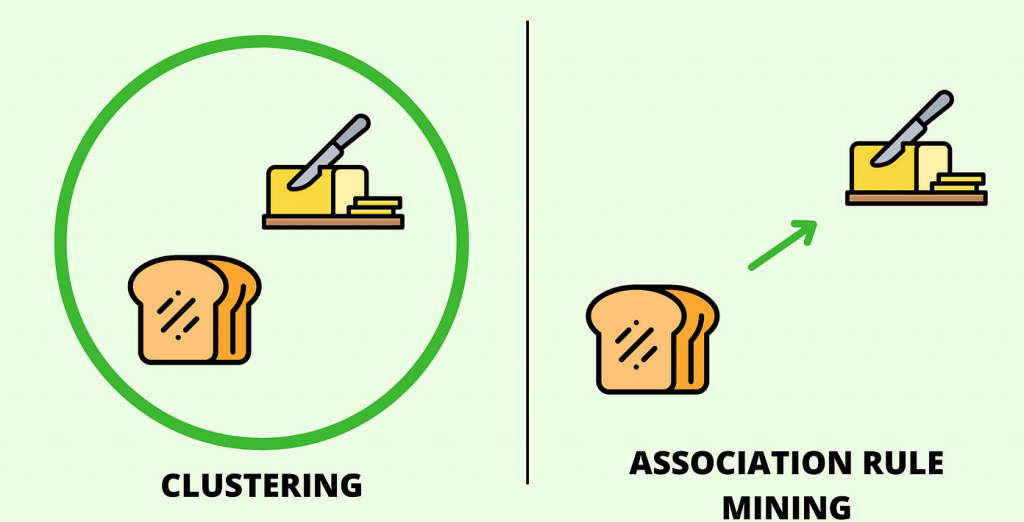
在关联规则挖掘中,有两个关键的指标:
关联规则挖掘的经典算法包括:
关联规则挖掘在商业和科学领域中得到了广泛的应用。例如,在零售业,通过分析顾客的购物篮,商家可以制定更有效的促销策略;在医学研究中,关联规则挖掘可以帮助发现患病的模式或者药物的副作用等。
时间序列分析是一种研究随时间变化而产生的数据的统计方法。时间序列是按照时间顺序排列的一系列数据点,通常是等间隔采集的观测结果。这些数据点可以用来分析时间的趋势、周期性、季节性和其他可能的模式。
时间序列分析主要包括以下几个方面:
时间序列分析在许多领域中都有应用,包括金融、经济学、气象学、生态学、医学等。通过深入理解时间序列的模式,人们可以更好地预测未来趋势,制定决策和规划。
空间数据分析是一种专注于处理和分析与地理位置相关的数据分析方法。这类数据包括地理信息、地理坐标、地形地貌等,通常以空间对象和它们在地球表面上的位置为基础。空间数据分析的目标是揭示地理空间中的模式、趋势和关联关系,从而帮助我们更好地理解地理现象、做出决策和规划。
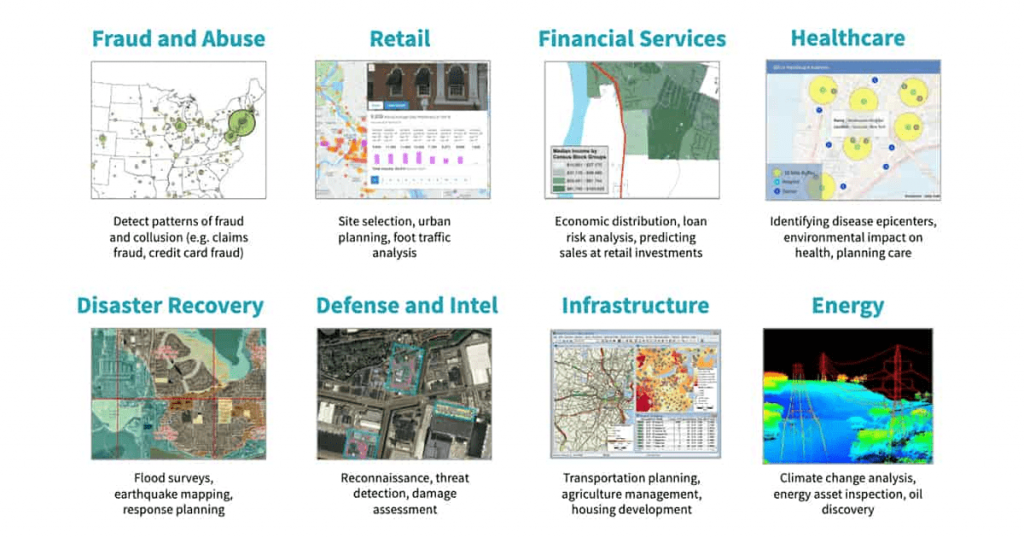
空间数据分析的主要内容包括:
空间数据分析应用的领域非常广泛,包括城市规划、环境科学、农业、流行病学、天文学等。这些分析不仅有助于对地理现象的理解,还为地理信息的管理和利用提供了科学的支持。
总体而言,数据分析方法丰富多样,适用于不同类型和规模的数据。在日益复杂和多变的商业环境中,精准的数据分析不仅仅是一项技能,更是决策制定和问题解决的利器。通过深入理解这些数据分析方法,我们能够更好地利用数据,发现隐藏在数字背后的故事,从而为未来的发展提供更有力的支持。无论是专业的数据科学家,还是对数据分析感兴趣的初学者,都值得深入研究这个充满活力的领域。
在数字化与信息化高速发展的时代,FineBI——市场占有率第一的BI数据分析软件,旨在帮助企业的业务人员充分了解和利用他们的数据,加速企业数字化转型,提升市场竞争力。得益于FineBI强劲的大数据引擎,用户只需简单拖拽便能制作出丰富多样的数据可视化信息,自由地对数据进行分析和探索,让数据释放出更多未知潜能。
如果您对BI以及数据可视化感兴趣,可以点击下方的图片或按钮,立即试用FineBI!
商业智能BI产品更多介绍:www.finebi.com