大数据应用背景
随着各个业务系统的不断增加,以及各业务系统数据量不断激增,IT数据支撑方的工作变得越来越复杂。主要问题如下:

多数据源整合
数据来自多个不同的业务系统,需要对接各种数据源并整合成统一数据仓库

数据体量大
积累的数据越来越多,数据体量越来越大,但对数据分析的要求越来越高

数据二次加工
获取到源数据后,往往都要再对数据进行清洗、删减、计算等二次加工操作
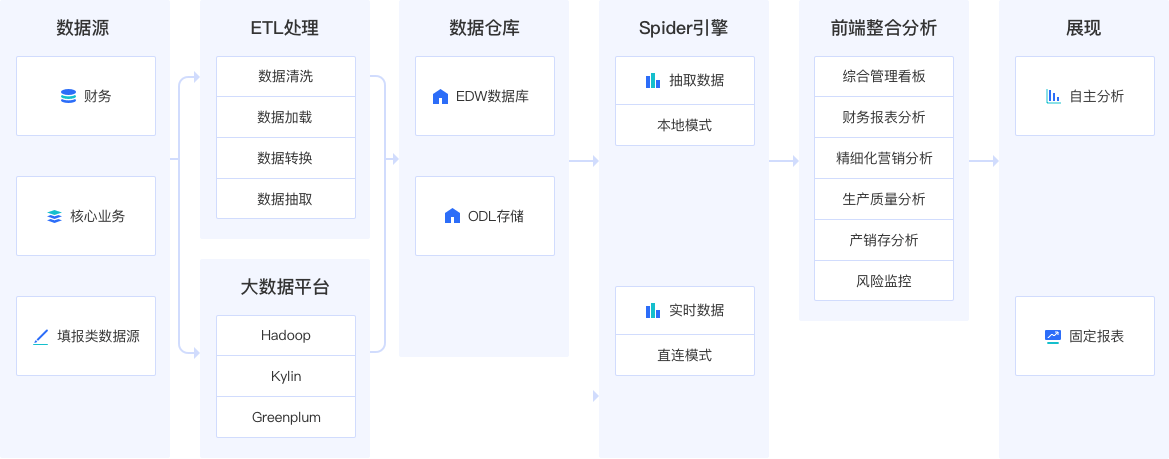
大数据分析架构图
基于Spider大数据引擎的直连模式和本地模式,可支撑BI数据分析的各种应用场景。
底层大数据技术
列式数据存储
抽取数据的存储是以列为单位的, 同一列数据连续存储,在查询时可以大幅降低I/O,提高查询效率,并且连续存储的列数据,具有更大的压缩单元和数据相似性,可以大幅提高压缩效率。
智能位图索引
位图索引即Bitmap索引,是处理大数据时加快过滤速度的一种常见技术,并且可以利用位图索引实现大数据量并发计算,并指数级的提升查询效率,同时我们做了压缩处理,使得数据占用空间大大降低。
数据本地化计算
为了减少网络传输的消耗,避免不必要的shuffle,利用Spark的调度机制实现数据本地化计算。在知道数据位置的前提下,将任务分配到拥有计算数据的节点上,节省了数据传输的消耗,完成巨量数据计算的秒级呈现。
智能缓存
直连模式下会直接和数据库对话,性能会受到数据库的限制,因此引入encache框架做智能缓存,以及针对返回数据之后的操作有多级缓存和智能命中策略,避免重复缓存,从而大幅提升查询性能。
典型应用场景
历史数据自助分析
业务需求
客户项目的底层为关系型数据库oracle和sqlserver,大量级数据多维度查询计算,若直接对接传统关系型数据库进行数据分析查询,就容易出现性能瓶颈
解决方案
采用Spider引擎的本地模式,将数据抽取到本地磁盘中,以二进制文件形式存放,查询计算时候多线程并行计算,完全利用可用CPU资源。从而在小数据量情况下,展示效果优异。计算引擎与Web应用放在同一服务器上,轻量方便。
达成效果
底层数仓实际最大单表数据量亿级以内,对于数据量较大的几个分析(数据量在5kw左右),数据库的查询需要耗费10min,抽取之后在3s之内就可以快速展示,大大提高了用户的分析效率。







专业的解决方案、先进的产品帮您 实现业务的爆发式增长